Available soon...
To perform adversarial attacks in the physical world, many studies have proposed adversarial camouflage, a method to hide a target object by applying camouflage patterns on 3D object surfaces. For obtaining optimal physical adversarial camouflage, previous studies have utilized the so-called neural renderer, as it supports differentiability. However, existing neural renderers cannot fully represent various real-world transformations due to a lack of control of scene parameters compared to the legacy photo-realistic renderers. In this paper, we propose the Differentiable Transformation Attack (DTA), a framework for generating a robust physical adversarial pattern on a target object to camouflage it against object detection models with a wide range of transformations. It utilizes our novel Differentiable Transformation Network (DTN), which learns the expected transformation of a rendered object when the texture is changed while preserving the original properties of the target object. Using our attack framework, an adversary can gain both the advantages of the legacy photo-realistic renderers including various physical-world transformations and the benefit of white-box access by offering differentiability. Our experiments show that our camouflaged 3D vehicles can successfully evade state-of-the-art object detection models in the photo-realistic environment (i.e., CARLA on Unreal Engine). Furthermore, our demonstration on a scaled Tesla Model 3 proves the applicability and transferability of our method to the real world.
| Photo-Realistic Simulation Demo | Real World Demo |
|---|---|
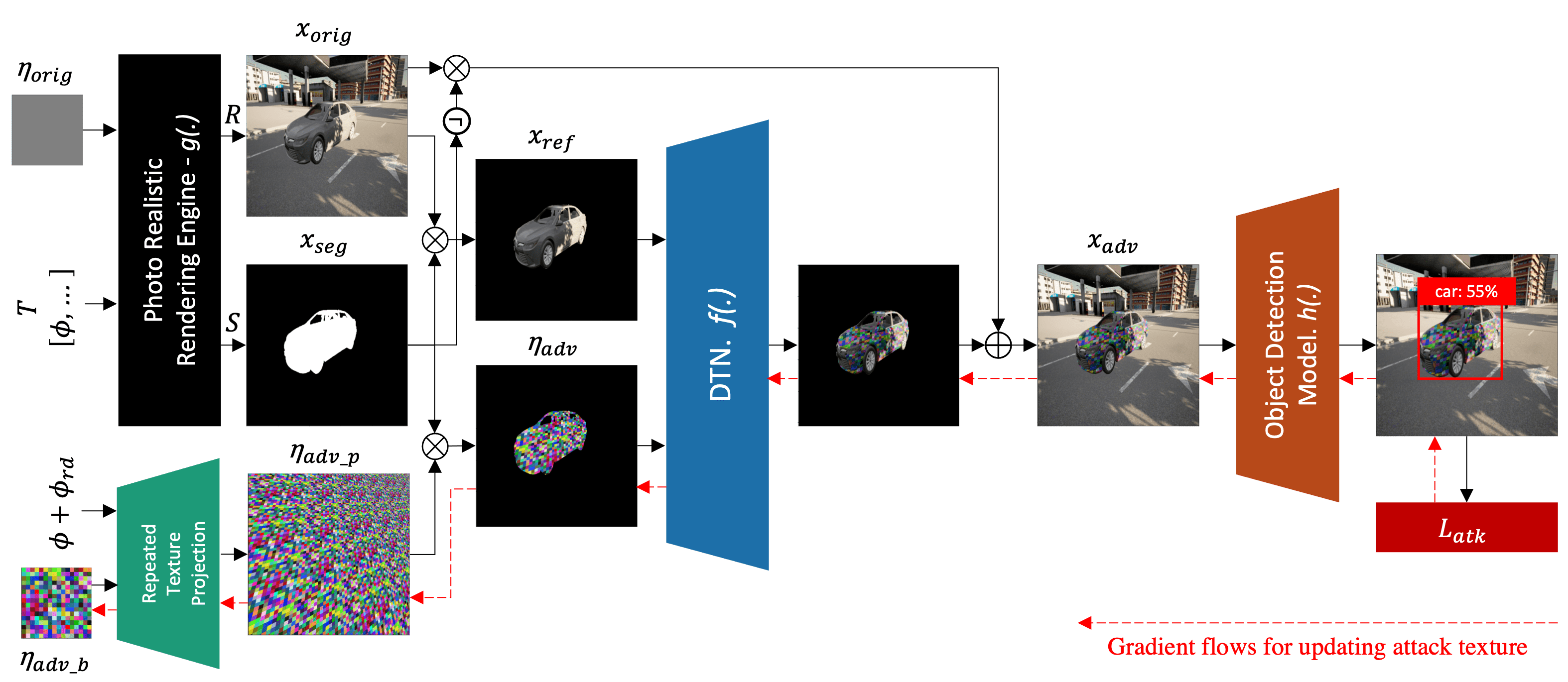
As shown in the top picture, DTA Framework consists of four components: Photo-Realistic Rendering Engine, Repeated Texture Projection Function, Differentiable Transformation Network (DTN), and the target Object Detection Model.
Photo-realistic rendering engine is any software that can produce a photo-realistic image which is similar to the real physical world. In our work, we use Carla Simulator (ver. 0.9.11) on Unreal Engine (ver. 4.2) to synthesize our dataset as well as to evaluate our generated texture on photo-realsitic simulation setting. We modify original code to allow car's texture modification. The video illustrates the output of the rendering engine we use.
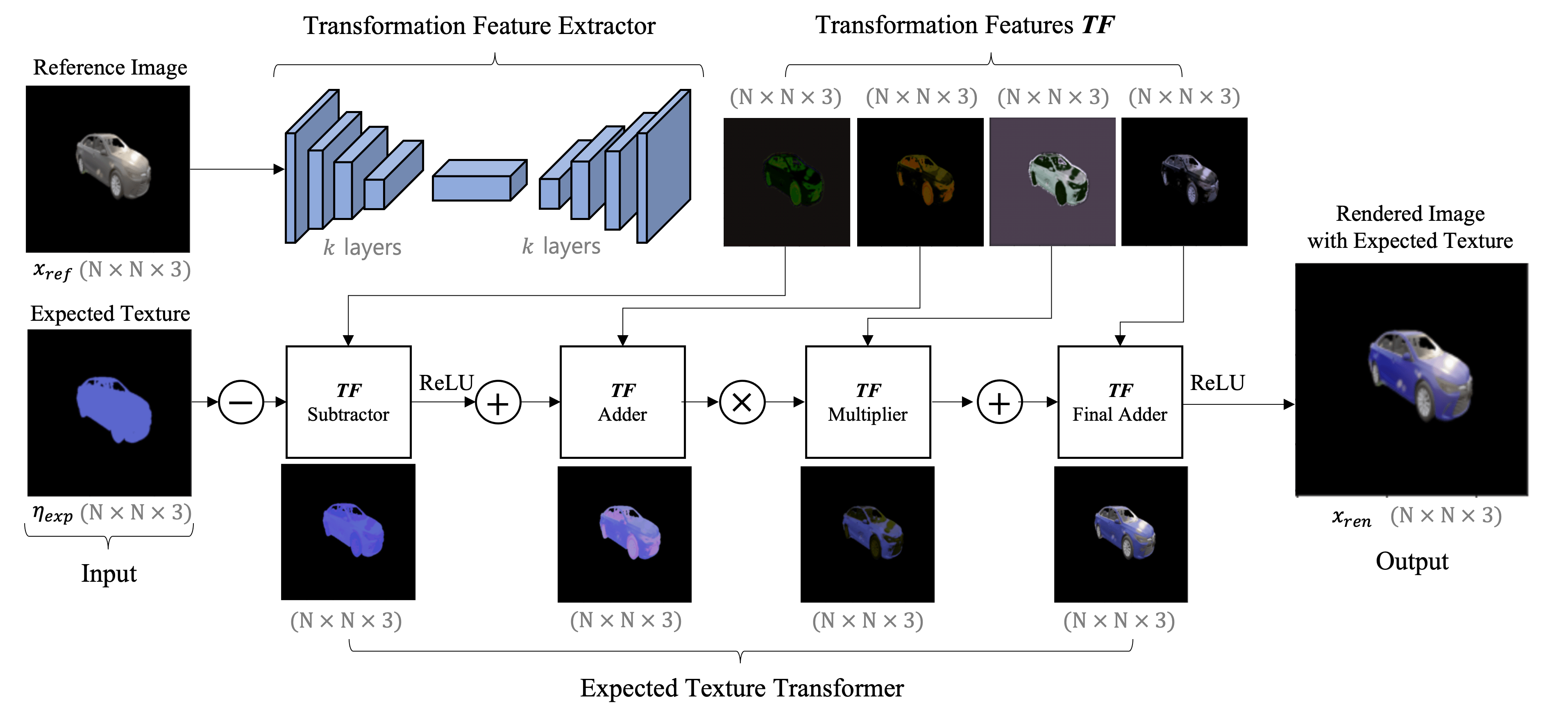
Our proposed DTN learns the expected transformation of a rendered object when the texture is changed while preserving the original properties of the target object. It relies on the photo-realistic image synthesized from a non-differentiable renderer to produce a differentiable version of the reference image after applying the expected texture. DTN is embedded as an extension to provide texture differentiability.
The video illustrates how our DTN can correctly predict the rendered image when the texture (color) is changed. The network retains the original target properties such as material, light reflection, and shadow from other objects.
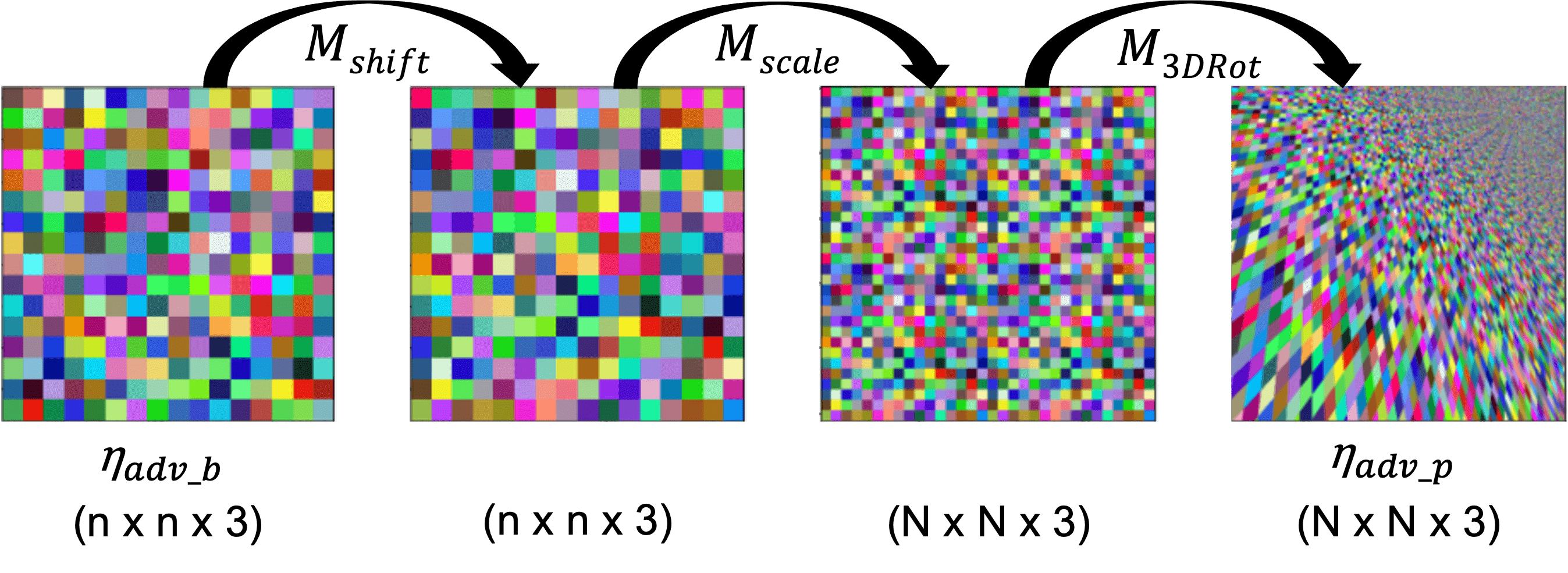
We propose a repeated pattern as our final attack camouflage texture. It has several benefits, such as ease of application because the texture can be used to cover the object while ignoring the texture mapping. As the application, we propose a Repeated Texture Projection Function for simply projecting the pattern with a sequence of operations by transformation matrix M. We use wrap mode for filling points outside boundaries, which extends the output by wrapping around the opposite edge, giving a repeated texture effect.
The video illustrates how our DTN + Repeated Texture Projection Function can be used to mimic the repeated pattern produced by the photo-realistic rendering engine. This gives us the differentiable version of the photo-realistic renderer, allowing us to use gradient-based optimization to find the optimum repeated attack texture.
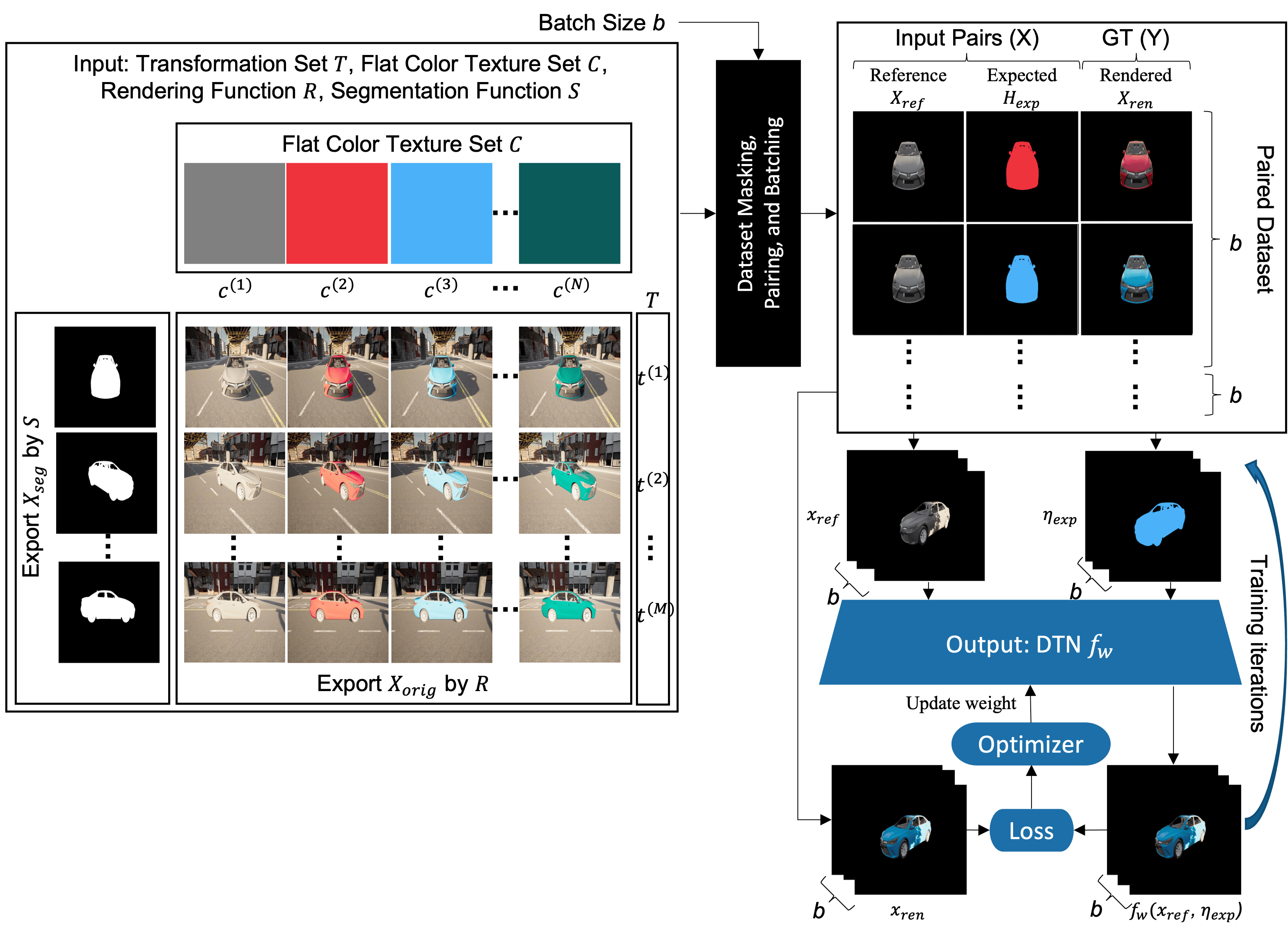
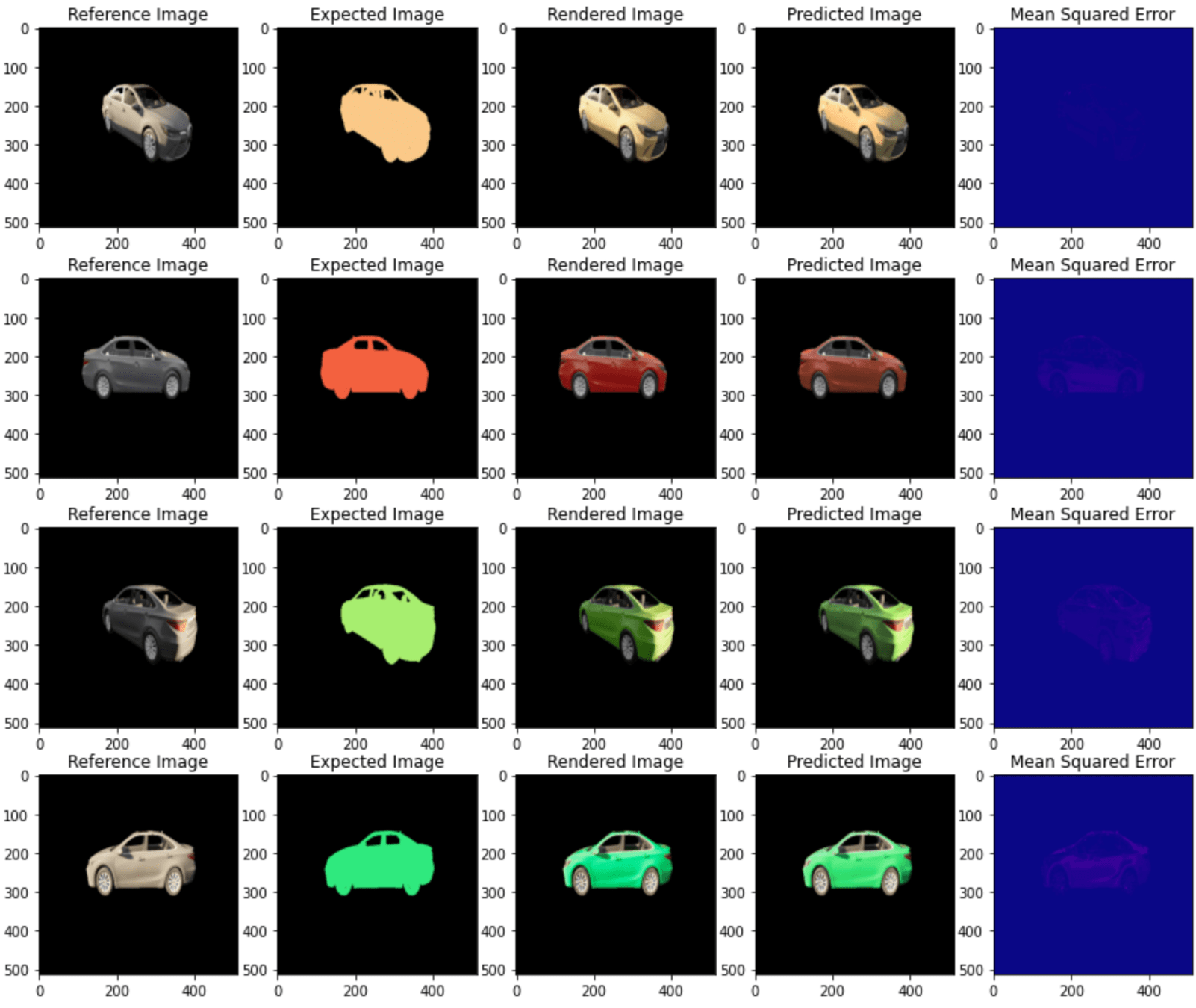
Before using DTA to generate the adversarial pattern, We need to train DTN with the dataset generated by the photo-realistic rendering engine (see the first video on how the dataset is generated). First, we select a set of random flat color textures and predefined transformations. Then, we use the rendering engine to produce the photo-realistic images that will later be used as reference image xref , expected texture ηexp , and ground truth of rendered image xren . See the figure on the right for DTN training diagram.
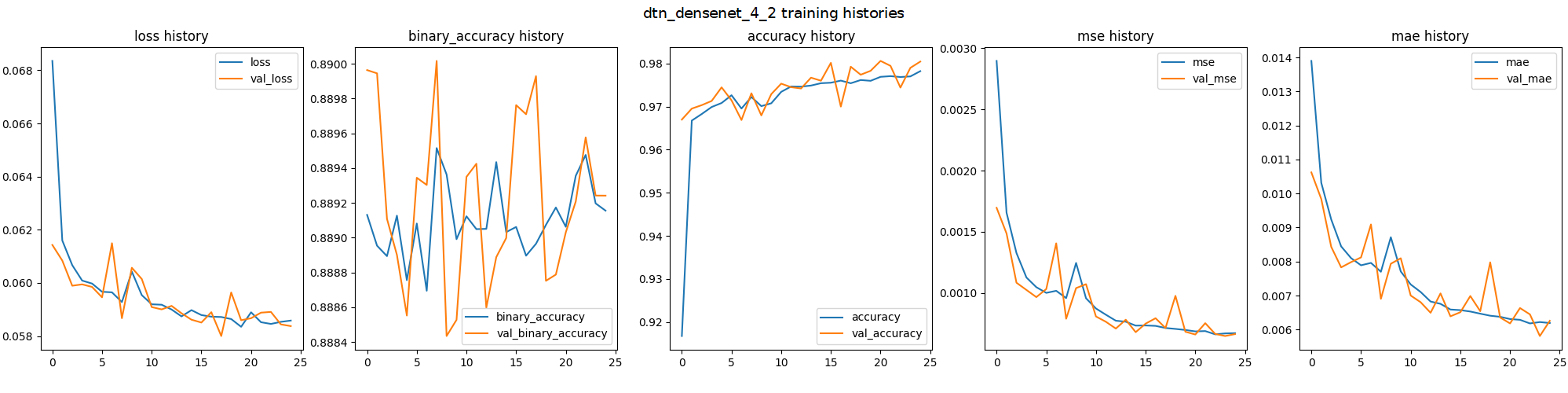
The training histories of DTN with DenseNet architecture and the prediction samples are shown below.
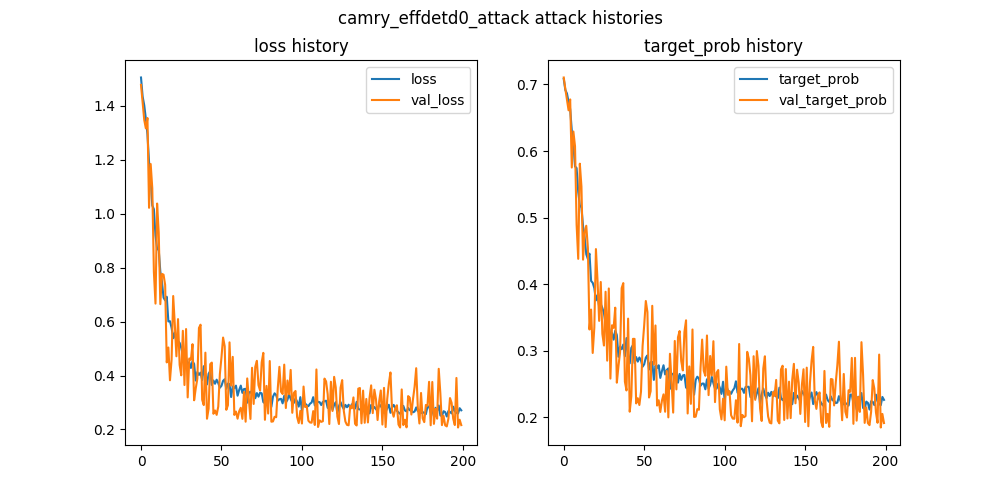
In the attack phase, the goal is to minimize the original target confidence score, which prevents the object detector from detecting the target object correctly. We use the differentiability of the complete DTA Framework to find the best adversarial pattern ηadv that minimizes the attack loss Latk by updating the ηadv based on the loss gradient. The right figure shows the training history for DTA targeting EfficientDetD0 model of Toyota Camry car.
The sample predictions of the DTA Framework consisting of standard, random (initial), and attack (final) textured cars are shown below. As we can random textured car is not sufficient to camouflage the car from the object detection model.

We compare our adversarial camouflage with a random pattern and previous works on 3D physical attacks: CAMOU, ER, UPC, and DAS We closely follow the approach to replicate the original papers, but we rebuild the environment and target models based on our evaluation setup (see supplementary material for the details). However, UPC and DAS have different settings to recreate in our environment; thus, we only evaluate them on the transferability experiment. Finally, we evaluate the transferability and applicability of our camouflage pattern in the real-world setting. We built two 1:10 scaled Tesla Model 3 using a 3D printer, each representing the normal and our camouflage texture. Then, we evaluate them in real-life locations, indoor and outdoor.
[Click the link to show sample demo videos]
[Click the link to show sample demo videos]

@InProceedings{Suryanto_2022_CVPR,
author = {Suryanto, Naufal and Kim, Yongsu and Kang, Hyoeun and Larasati, Harashta Tatimma and
Yun, Youngyeo and Le, Thi-Thu-Huong and Yang, Hunmin and Oh, Se-Yoon and Kim, Howon},
title = {DTA: Physical Camouflage Attacks Using Differentiable Transformation Network},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {15305-15314}
}

DTA: Physical Camouflage Attacks using Differentiable Transformation Network
Naufal Suryanto, Yongsu Kim, Hyoeun Kang, Harashta Tatimma Larasati, Youngyeo Yun, Thi-Thu-Huong Le, Hunmin Yang, Se-Yoon Oh, Howon Kim